Envoi de données
Pour pouvoir ajouter des données, vous devez créer une structure de fichier et ajouter un column mapping. Un column mapping est une liste de colonnes décrivant un document (.CSV, .XLSX, .XLS).
Pour ajouter un column mapping, vous devez d'abord définir la structure du fichier :
filestructure = FileStructure(
file_type=FileType.xlsx,
charset="UTF-8",
delimiter=",",
quote_char='"',
escape_char='\\',
eol_char="\\r\\n",
comment_char="#",
header=True,
sheet_name="Sheet1"
)
Il est important de noter qu'à part le file_type (qui peut être défini comme CSV, XLSX ou XLS) et le sheet_name (qui est optionnel), les attributs ci-dessus sont définis par défaut.
Cela signifie qu'à moins que la valeur de votre attribut soit différente, vous n'avez pas besoin de le définir.
Maintenant, un column mapping peut être créée :
column_list = [
Column('<Column name>', <Column index>, <Column Type>),
Column('<Column name>', <Column index>, <Column Type>),
Column('<Column name>', <Column index>, <Column Type>, time_format='<Your time format>')
]
column_mapping = ColumnMapping(column_list)
Column nameest le nom de la colonne.Column indexest l'index de la colonne dans votre fichier. Notez que l'index de la colonne commence à 0.Colulmn Typeest le type de la colonne. Il peut s'agir deCASE_ID,TASK_NAME,TIME,METRIC(une valeur numérique) ouDIMENSION(peut être une chaîne de caractères).
Veuillez noter que votre format horaire doit utiliser le format Java SimpleDateFormat .
Cela signifie que vous devez marquer la date en utilisant les lettres suivantes (selon votre format de date) :
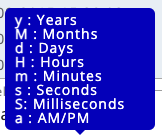
Par exemple, votre format de date peut ressembler à ceci :
yyyy-MM-dd HH:mm:ss.SSSSSS
Dans les exemples suivants, n'oubliez pas de changer le time_format avant d'utiliser le code.
Il est également possible de vérifier si un column mapping existe ou non :
my_project.column_mapping_exists
En outre, une colonne peut également être créée à partir d'un JSON.
json_str = '{"name": "test", "columnIndex": "1", "columnType": "CASE_ID"}'
column = Column.from_json(json_str)
Par conséquent, un column mapping peut également être créé à partir d'un dictionnaire de colonnes JSON. Par exemple:
column_dict = '''{
"col1": {"name": "case_id", "columnIndex": "0", "columnType": "CASE_ID"},
"col2": {"name": "task_name", "columnIndex": "1", "columnType": "TASK_NAME"},
"col3": {"name": "time", "columnIndex": "2", "columnType": "TIME", "format": "yyyy-MM-dd'T'HH:mm"}
}'''
column_mapping = ColumnMapping.from_json(column_dict)
Le Column Mapping peut également être créé à partir d'une liste de colonnes JSON. La principale différence entre la liste et le dictionnaire est que dans le dictionnaire, vous devez énoncer le numéro de la colonne avant de donner les autres informations.
column_list = '''[
{"name": "case_id", "columnIndex": "0", "columnType": "CASE_ID"},
{"name": "task_name", "columnIndex": "1", "columnType": "TASK_NAME"},
{"name": "time", "columnIndex": "2", "columnType": "TIME", "format": "yyyy-MM-dd'T'HH:mm"}
]'''
column_mapping = ColumnMapping.from_json(column_list)
De plus, il est possible de retourner le format dictionnaire JSON de la colonne avec la méthode to_dict().
En faisant cela, nous pouvons alors créer un column mapping avec la méthode from_json().
La fonction json.dumps() convertit un sous-ensemble d'objets Python en une chaîne JSON.
column_list = [
Column('case_id', 0, ColumnType.CASE_ID),
Column('task_name', 1, ColumnType.TASK_NAME),
Column('time', 2, ColumnType.TIME, time_format="yyy-MM-dd'T'HH:mm")
]
column_mapping = ColumnMapping(column_list)
json_str = json.dumps(column_mapping.to_dict())
column_mapping = ColumnMapping.from_json(json_str)
Après l'avoir crée, le column mapping peut être ajouté:
my_project.add_column_mapping(filestructure, column_mapping)
Finalement, vous pouvez ajouter vos fichiers de type CSV, XLSX or XLS:
wg = Workgroup(w_id, w_key, api_url, auth_url)
p = Project("<Your Project ID>", wg.api_connector)
filestructure = FileStructure(
file_type=FileType.xlsx,
sheet_name="Sheet1"
)
column_list = [
Column('Case ID', 0, ColumnType.CASE_ID),
Column('Start Timestamp', 1, ColumnType.TIME, time_format="yyyy-MM-dd'T'HH:mm"),
Column('Complete Timestamp', 2, ColumnType.TIME, time_format="yyyy-MM-dd'T'HH:mm"),
Column('Activity', 3, ColumnType.TASK_NAME),
Column('Ressource', 4, ColumnType.DIMENSION),
]
column_mapping = ColumnMapping(column_list)
p.add_column_mapping(filestructure, column_mapping)
p.add_file("ExcelExample.xlsx")
En outre, des tâches groupées peuvent également être déclarées si nécessaire. Si une tâche groupée est créée dans une colonne, des tâches groupées doivent également être déclarées dans d'autres colonnes, car elles ne peuvent pas fonctionner individuellement :
column_list = [
Column('case_id', 0, ColumnType.CASE_ID),
Column('time', 1, ColumnType.TIME, time_format="yyyy-MM-dd'T'HH:mm"),
Column('task_name', 2, ColumnType.TASK_NAME, grouped_tasks_columns=[1, 3]),
Column('country', 3, ColumnType.METRIC, grouped_tasks_aggregation=MetricAggregation.FIRST),
Column('price', 4, ColumnType.DIMENSION, grouped_tasks_aggregation=GroupedTasksDimensionAggregation.FIRST)
]
column_mapping = ColumnMapping(column_list)
Les grouped_tasks_columns représentent la liste des indices des colonnes qui doivent être groupées.
Si grouped_tasks_columns est déclaré, il doit au moins avoir l'index d'une colonne de type TASK_NAME
et l'index d'une colonne de type METRIC, DIMENSION ou TIME. Elle ne doit pas avoir l'index d'une colonne de type CASE_ID.
L'agrégation grouped_tasks_aggregation représente l'agrégation des tâches groupées.
De plus, si le type de colonne d'une agrégation de tâches groupées est METRIC, alors le type de la tâche groupée doit être de type MetricAggregation.
De même, si le type de colonne d'une agrégation de tâches groupées est DIMENSION, alors le type de la tâche groupée doit être de type GroupedTasksDimensionAggregation.
Enfin, si grouped_tasks_columns est déclaré, le type de la colonne doit être TASK_NAME.