Tâches groupées
Tâches groupées
Lorsque l'on définit le Column Mapping, nous pouvons aussi définir de manière facultative un ensemble de colonnes à utiliser pour regrouper ensemble des événements qui ont des valeurs identiques (dans les colonnes définies). Les événements sont groupés à l'intérieur de leur cas, et des agrégations doivent être définies pour les dimensions et les métriques.
L'idée de cette fonctionnalité est de regrouper plusieurs événements similaires en un seul événement.
Exemple de tâches groupées
Prennons les événements suivants à titre d'exemple :
| CaseId | Activité | Début | Fin | Pays | Ville | Prix |
|---|---|---|---|---|---|---|
| 1 | A | 10/10/10 08:38 | 11/10/10 08:38 | France | Paris | 10 |
| 1 | B | 10/10/10 09:40 | 11/10/10 09:40 | Allemagne | Berlin | 20 |
| 1 | A | 10/10/10 10:42 | 11/10/10 10:42 | France | Toulouse | 30 |
| 1 | C | 10/10/10 11:50 | 11/10/10 11:50 | Allemage | Munich | 10 |
| 1 | C | 10/10/10 12:50 | 11/10/10 12:50 | Allemagne | Hamburg | 20 |
| 2 | A | 10/10/10 08:20 | 11/10/10 08:20 | France | Rennes | 5 |
| 2 | B | 10/10/10 09:30 | 11/10/10 09:30 | Allemagne | Berlin | 10 |
| 2 | A | 10/10/10 10:40 | 11/10/10 10:40 | France | Bordeaux | 25 |
| 2 | A | 10/10/10 11:50 | 11/10/10 11:50 | USA | New York | 10 |
Quand vous ajoutez ce fichier à un projet vide, lors de la sélection de la colonne d'activité/tâche, une petite boîte Colonnes à utiliser comme identifiants de tâches uniques apparait comme montré dans cette image :
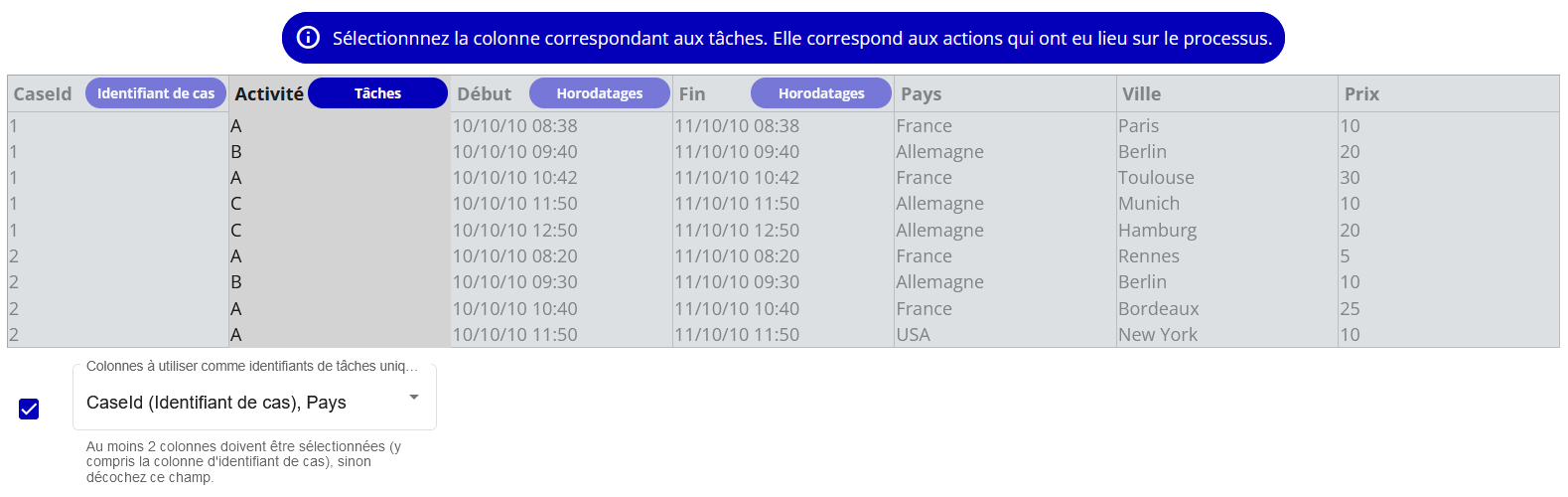
Ici les colonnes sélectionnées pour le regroupement sont CaseId et Pays. Cela signifie que lors du traitement du fichier dans la plateforme de Mining, tous les événements qui partagent les mêmes valeurs pour les colonnes CaseId, Activité et Pays seront réunis en un seul événement.
Vous pouvez aussi déselectionner l'option si vous ne voulez pas regrouper les événements similaires en un seul événement.
Quand un groupe est défini, il est nécessaire de définir aussi une agrégation des tâches groupées pour toutes les dimensions et métriques que vous avez ajoutés au column mapping. En effet, comme plusieurs événements pouvant avoir des valeurs différentes pour leurs dimensions et métriques vont être réunis en un seul événement, vous devez définir une agrégation pour déclarer la valeur que vous souhaitez obtenir pour ce nouvel événement unique.
Pour les dimensions:
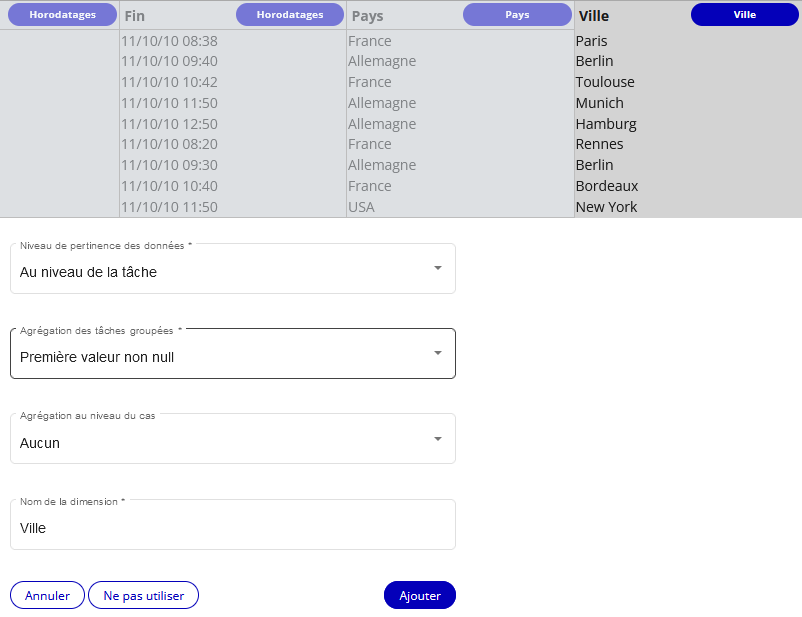
Comme présenté avec l'image suivante, j'ai sélectionné "Première valeur non null" dans la boîte "Agrégation des tâches groupées" pour la colonne de dimension Ville.
Pour les agrégations de tâches groupées liées aux colonnes de dimension, vous avez le choix entre :
- Première valeur non null
- Dernière valeur non null
Pour les métriques:
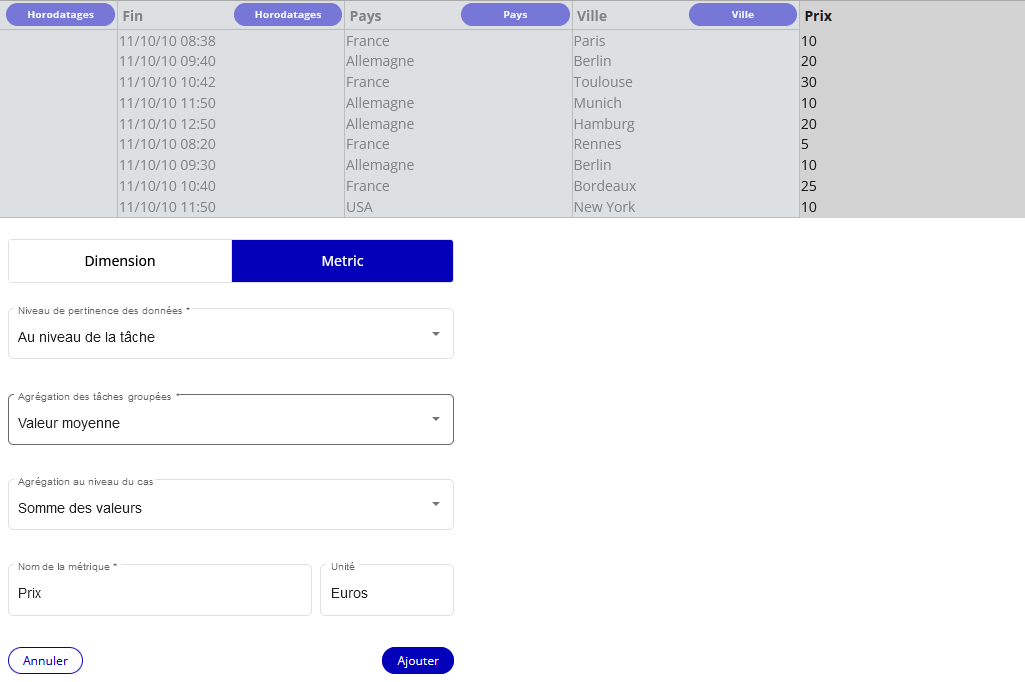
Comme présenté avec l'image suivante, j'ai sélectionné "Valeur moyenne" dans la boîte "Agrégation des tâches groupées" pour la colonne de métrique Prix.
Pour les agrégations de tâches groupées liées aux colonnes de métrique, vous avez le choix entre :
- Première valeur non null
- Dernière valeur non null
- Valeur minimum
- Valeur maximum
- Valeur moyenne
- Valeur médiane
- Somme des valeurs
Par conséquent, à l'intérieur d'un cas, tous les événements qui ont les mêmes valeurs pour les colonnes CaseId, Activité et Pays seront regroupés ensemble, et les nouvelles valeurs pour les colonnes de dimension et de métrique sont calculées en fonction de l'agrégation de tâches groupées associée à chaque colonne.
Si les colonnes de temps ne sont pas définies dans les colonnes à utiliser pour le regroupement (ici les colonnes Début et Fin ne sont pas définies dans la boîte Colonnes à utiliser comme identifiants de tâches uniques), nous n'avons pas à définir d'agrégation comme pour les dimensions ou métriques: * La date la plus petite parmi tous les événements d'un groupe sera utilisée comme la nouvelle date de début par le nouvel événement unique. * La date la plus grande parmi tous les événements d'un groupe sera utilisée comme la nouvelle date de fin par le nouvel événement unique.
Après la validation du column mapping final, et lors de l'ingestion du fichier, certains événements vont être regroupés ensemble de la façon suivante :
Pour le CaseId 1: * Les premier et troisième événements de ce cas ont les mêmes valeurs pour leurs colonnes Activité (A) et Pays (France). De ce fait, ils sont groupés ensemble pour ne faire qu'un seul événement de tâche A et de pays France. * Le second événement de ce cas n'est pas groupé. En effet, aucun autre événement de ce cas n'a de tâche nommée B et de pays nommé Allemagne. * Les quatrième et cinquième événements de ce cas ont les mêmes valeurs pour leurs colonnes Activité (C) et Pays (Allemagne). De ce fait, ils sont groupés ensemble pour ne faire qu'un seul événement de tâche C et de pays Allemagne.
Pour le CaseId 2: * Les premier et troisième événements de ce cas ont les mêmes valeurs pour leurs colonnes Activité (A) et Pays (France). De ce fait, ils sont groupés ensemble pour ne faire qu'un seul événement de tâche A et de pays France. * Le second événement de ce cas n'est pas groupé. En effet, aucun autre événement de ce cas n'a de tâche nommée B et de pays nommé Allemagne. * Le quatrième événement de ce cas n'est pas groupé. Il a la même Activité (A) que les premier et troisième événements du cas, mais son Pays (USA) est différent.
Après le regroupement des événements similaires, on obtient cette nouvelle liste d'événements :
| CaseId | Activité | Début | Fin | Pays | Ville | Prix |
|---|---|---|---|---|---|---|
| 1 | A | 10/10/10 08:38 | 11/10/10 10:42 | France | Paris | 20 |
| 1 | B | 10/10/10 09:40 | 11/10/10 09:40 | Allemagne | Berlin | 20 |
| 1 | C | 10/10/10 11:50 | 11/10/10 12:50 | Allemagne | Munich | 15 |
| 2 | A | 10/10/10 08:20 | 11/10/10 10:40 | France | Rennes | 15 |
| 2 | B | 10/10/10 09:30 | 11/10/10 09:30 | Allemagne | Berlin | 10 |
| 2 | A | 10/10/10 11:50 | 11/10/10 11:50 | USA | New York | 10 |
Pour le CaseId 1: * Le premier événement de ce cas dans la nouvelle liste d'événements a été créé par regroupement des premier et troisième événements de ce cas dans la liste initiale d'événements (celle avant regroupement). * CaseId valait 1 pour les deux événements qui ont été regroupés, donc la valeur reste à 1 pour le nouvel événement unique. * Activité valait A pour les deux événements qui ont été regroupés, donc la valeur reste à A pour le nouvel événement unique. * Début valait 10/10/10 08:38 pour le premier événement qui a été groupé, et 10/10/10 10:42 pour le second. La date la plus petite (10/10/10 08:38) est donc utilisée en tant que date de début pour le nouvel événement unique. * Fin valait 11/10/10 08:38 pour le premier événement qui a été groupé, et 11/10/10 10:42 pour le second. La date la plus grande (11/10/10 10:42) est donc utilisée en tant que date de fin pour le nouvel événement unique. * Pays valait France pour les deux événements qui ont été regroupés, donc la valeur reste à France pour le nouvel événement unique. * Ville valait Paris pour le premier événement qui a été groupé, et Toulouse pour le second. Dans le column mapping, Première valeur non null a été définie en tant qu'Agrégation des tâches groupées pour cette dimension, par conséquent, comme Paris était la première valeur, c'est celle utilisée pour le nouvel événement unique. * Prix valait 10 pour le premier événement qui a été groupé, et 30 for le second. Dans le column mapping, Valeur moyenne a été définie en tant qu'Agrégation des tâches groupées pour cette métrique, par conséquent, 20 est la valeur de cette métrique pour le nouvel événement unique (20 étant le résultat de la moyenne entre 10 et 30). * Le second événement de ce cas dans la nouvelle liste d'événements est identique au second événement de ce cas dans la liste initiale d'événements (celle avant regroupement), puisqu'il n'était pas possible de le regrouper avec d'autres événements. * Le troisième événement de ce cas dans la nouvelle liste d'événements a été créé par regroupement des quatrièmes et cinquième événements de ce cas dans la liste initiale d'événements (celle avant regroupement). * CaseId valait 1 pour les deux événements qui ont été regroupés, donc la valeur reste à 1 pour le nouvel événement unique. * Activité valait C pour les deux événements qui ont été regroupés, donc la valeur reste à C pour le nouvel événement unique. * Début valait 10/10/10 11:50 pour le premier événement qui a été groupé, et 10/10/10 12:50 pour le second. La date la plus petite (10/10/10 11:50) est donc utilisée en tant que date de début pour le nouvel événement unique. * Fin valait 11/10/10 11:50 pour le premier événement qui a été groupé, et 11/10/10 12:50 pour le second. La date la plus grande (11/10/10 12:50) est donc utilisée en tant que date de fin pour le nouvel événement unique. * Pays valait Allemagne pour les deux événements qui ont été regroupés, donc la valeur reste à Allemagne pour le nouvel événement unique. * Ville valait Munich pour le premier événement qui a été groupé, et Hamburg pour le second. Dans le column mapping, Première valeur non null a été définie en tant qu'Agrégation des tâches groupées pour cette dimension, par conséquent, comme Munich était la première valeur, c'est celle utilisée pour le nouvel événement unique. * Prix valait 10 pour le premier événement qui a été groupé, et 20 for le second. Dans le column mapping, Valeur moyenne a été définie en tant qu'Agrégation des tâches groupées pour cette métrique, par conséquent, 15 est la valeur de cette métrique pour le nouvel événement unique (15 étant le résultat de la moyenne entre 10 et 20).
Pour le CaseId 2: * Le premier événement de ce cas dans la nouvelle liste d'événements a été créé par regroupement des premier et troisième événements de ce cas dans la liste initiale d'événements (celle avant regroupement). * CaseId valait 2 pour les deux événements qui ont été regroupés, donc la valeur reste à 2 pour le nouvel événement unique. * Activité valait A pour les deux événements qui ont été regroupés, donc la valeur reste à A pour le nouvel événement unique. * Début valait 10/10/10 08:20 pour le premier événement qui a été groupé, et 10/10/10 10:40 pour le second. La date la plus petite (10/10/10 08:20) est donc utilisée en tant que date de début pour le nouvel événement unique. * Fin valait 11/10/10 08:20 pour le premier événement qui a été groupé, et 11/10/10 10:40 pour le second. La date la plus grande (11/10/10 10:40) est donc utilisée en tant que date de fin pour le nouvel événement unique. * Pays valait France pour les deux événements qui ont été regroupés, donc la valeur reste à France pour le nouvel événement unique. * Ville valait Rennes pour le premier événement qui a été groupé, et Bordeaux pour le second. Dans le column mapping, Première valeur non null a été définie en tant qu'Agrégation des tâches groupées pour cette dimension, par conséquent, comme Rennes était la première valeur, c'est celle utilisée pour le nouvel événement unique. * Prix valait 5 pour le premier événement qui a été groupé, et 25 for le second. Dans le column mapping, Valeur moyenne a été définie en tant qu'Agrégation des tâches groupées pour cette métrique, par conséquent, 15 est la valeur de cette métrique pour le nouvel événement unique (15 étant le résultat de la moyenne entre 5 et 25). * Le second événement de ce cas dans la nouvelle liste d'événements est identique au second événement de ce cas dans la liste initiale d'événements (celle avant regroupement), puisqu'il n'était pas possible de le regrouper avec d'autres événements. * Le troisième événement de ce cas dans la nouvelle liste d'événements est identique au quatrième événement de ce cas dans la liste initiale d'événements (celle avant regroupement), puisqu'il n'était pas possible de le regrouper avec d'autres événements.
Cette nouvelle liste d'événements est ensuite utilisée en tant que donnée dans le projet de Mining.